

Humans can understand and learn, and animals have also demonstrated great learning ability. With this ability to learn, we can also adapt, and I recently read about a kea parrot in New Zealand missing his upper beak, who adapted so successfully that he became the alpha male of his circus. This type of open-ended adaptation to reshape the status quo is what we intuitively recognize as intelligence.
In contrast, the AI systems now reshaping economies are extraordinary autocomplete engines, with remarkable capacity to extend patterns of almost any kind, but genuine human-like understanding and agentic learning are not happening yet. Cognitive science and reinforcement learning research are showing us what could still be achieved.
Reinforcement learning formalizes how agents learn from reward, feedback and exploration, and the computational neuroscience literature draws parallels between brain mechanisms and RL-like computations. In AI systems, modern transformer systems increasingly use RL-style post-training methods such as RLHF and RL with verifiable rewards to shape behavior beyond what next-token prediction can produce.
Cognitive science research goes further, focusing on the mechanisms by which humans and animals think, learn, remember and act with agency, and these mechanisms remain underutilized in mainstream AI development. While much of what we may do day-in and day-out can become habitual, and while our brains are constantly predicting what comes next, we are not autocompleting our situations.
Of these many cognitive capabilities, memory retrieval is where this post focuses. I want to demonstrate how holographic reduced representations (HRR) can augment transformer performance by encoding cognitively grounded features.
The Setup
For a small research project, I investigated whether extending transformer-based contextual embeddings with cognitively grounded linguistic features could improve automated text classification from two distinct online communities. The study first extracted four cognitive markers as measurable features, namely first-person pronoun density, emotion ratios, binary language and social references, from a Kaggle Reddit dataset of both clinically relevant and neutral control posts (overall median of 84 tokens, mean of 176 tokens).
Two classification pipelines were then compared, with a baseline combining TF-IDF features with Naïve Bayes, and a hybrid model that concatenates DistilBERT sentence embeddings with HRR encoding of the cognitive-linguistic features, fed into a Logistic Regression classifier. DistilBERT was chosen for its compact size and reproducibility on standard user hardware.
DistilBERT and HRR
The hybrid method generated 768-dimensional DistilBERT [CLS] embeddings to capture the contextualized semantics, such as nuance, negation and narrative. The HRR encoder (Kelly and Tomkins-Flanagan, 2016) converts each of the four cognitive-linguistic features into a 256-dimensional vector. Each feature is assigned a dedicated role-filler pair, where the role and filler are bound together using circular convolution. The resulting four bound vectors are then combined by superposition (vector addition) into a single 256-dimensional summary vector for each post. These DistilBERT and HRR vectors are concatenated using a horizontal stack, producing a 1,024-dimensional hybrid representation, which is then classified using Logistic Regression.
The Results
The results from the baseline model are already strong, achieving a macro F1 score of 0.83 based on high precision for the neutral control group and high recall for the clinically relevant group. The DistilBERT ⊕ HRR + LR model improved upon those results and achieved a macro F1 of 0.93. The classification results for both the baseline and hybrid models are shown below, for both post categories.
| Baseline Precision | Baseline Recall | Hybrid Precision | Hybrid Recall | |
| Neutral Control | 0.97 | 0.64 | 0.93 | 0.94 |
| Clinically Relevant | 0.74 | 0.98 | 0.94 | 0.93 |
| 5-fold CV macro F1 | 0.832 | 0.927 |
While this represents a substantial improvement, it is important to note that the increase of the F1 score mainly reflects improved precision for the clinically relevant group, and improved recall for the neutral control group. These are important results, but the real-world priority of minimizing false negatives in the clinically relevant group was already achieved with the baseline model. It is also worth noting that the baseline and hybrid pipelines differ in both their features and their classifier, so a more complete comparison would hold the classifier fixed and vary the feature representation to isolate how much of the gain comes from the embedding upgrade versus the structured binding itself. Finally, domain-adapted encoders for Reddit posts would likely also close some of this gap.
Nonetheless, the results from the hybrid model highlight that cognitively structured memory features substantially improved the overall classification accuracy for both types of posts. This is shown in the following figure, which plots the ROC curves and the Precision-Recall curves for the two models, with the baseline model shown in solid blue and the hybrid DistilBERT ⊕ HRR + LR model shown in dashed red.
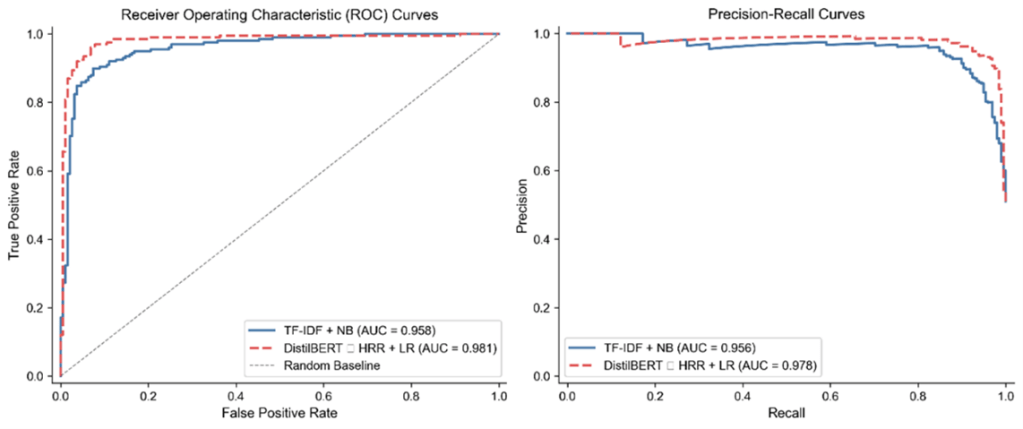
This study demonstrated that cognitive grounding improved the performance of NLP models used for text classification tasks. Importantly, leveraging HRR vectors as memory traces for specific cognitive traits produced a representation that improved classification for both post categories. While this was a simple project, it does highlight that targeted and innovative solutions can improve the metrics of AI models. Transformers have demonstrated significant capabilities, but these models still have specific limitations, and targeted gains, such as reducing false positive predictions, are possible.
Future Work
This project focused on only one specific aspect of cognitive science, memory retrieval, and only on one type of memory. The HRR vectors represent content addressable memory where items can be recalled from partial cues, just as we can recognize a familiar face from a quick glimpse or fill in a half-heard word from context. There are many other memory mechanisms that can be investigated to extend the capabilities of transformer models. As noted earlier, cognitive science research includes many other frameworks for how humans and animals think, learn, remember and act with agency, and incorporating these will be key to building more capable systems. Sophisticated autocompletion systems are creating tremendous opportunities, but they also leave a margin for improvement, especially as we begin to incorporate more detailed cognitive mechanisms into their design.
Bruce embodies the kind of thinking, learning and adaptability this post is about, so this one is dedicated to him!

Acknowledgements
I use Perplexity Pro and Claude Pro for personal and work activities daily, as well as ChatGPT Plus, Gemini Pro and Mistral Pro.
This post was fundamentally authored by me, including the ideas, research, coding and modeling discussed. Claude Pro and Perplexity Pro were used to review the text and make suggestions, and the changes were manually reviewed and implemented by me.
Sources
Kelly, M.A., Arora, N., West, R.L. and Reitter, D. (2020), Holographic Declarative Memory: Distributional Semantics as the Architecture of Memory. Cognitive Science, 44: e12904. https://doi.org/10.1111/cogs.12904
Kelly, M. A. and Tomkins-Flanagan, E. (2016). HRR: Holographic reduced representations. Software. Available from: https://github.com/ecphory/hrr
Mollick, E. (2024, October 19). Thinking like an AI. One Useful Thing. https://www.oneusefulthing.org/p/thinking-like-an-ai
Nelson, X. J. (2026, April 19). See Bruce the parrot wield his broken beak like a deadly weapon. Scientific American. https://www.scientificamerican.com/article/see-bruce-the-parrot-wield-his-broken-beak-like-a-deadly-weapon/
Plate, T. A. (1995). Holographic reduced representations. IEEE Transactions on Neural Networks, 6(3):623–641.
